



苏ICP备112451047180号-6
基于机器学习的机械臂控制系统的设计与实现
摘 要
随着科学技术的不断发展,人类社会的生产力不断提高,特别是工厂自动化,智能化后大大提高了生产力,其中机械臂占据着重要的地位。传统的机械臂的控制方法是建立在基于任务的精确数学模型之上,缺少一定的自适应性,如果生产环境发生改变时,控制效果会大打折扣甚至失效。随着人工智能的发展,将深度学习和强化学习引入到机械臂的控制中,成为一种解决方法。
为了提升机械臂的自适应性,本系统采用了机器学习中的强化学习和深度强化学习的方法,对Q学习[1][2]、深度Q网络[3][4][5]、策略梯度[6]、演员评论家[7][8][9]、深度确定性策略梯度算法[10]进行了讨论和尝试,并使用了后见经验回放[11]和层次强化学习[12]进行稀疏奖励求解,也尝试了对奖励进行重塑提高收敛速度的方法。实验结果表明:深度确定性策略梯度算法可以有效的进行机械臂的控制,并且奖励重塑和事后经验回放可以有效提高智能体在训练时的收敛速度。
关键词:深度学习 强化学习 机械臂 人工智能
目 录
摘 要 I
Abstract II
1 绪论 1
2 实验环境搭建 2
2.1 可视化处理 2
2.2 环境设计 2
2.3 Gym环境 3
2.3 智能体的搭建环境 3
3 智能体的设计和测试 5
3.1 马尔可夫决策 5
3.2 Q-Learning 6
3.3 Deep Q Network 8
3.4 Policy Gradients 11
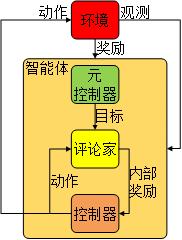
3.5 Actor-Critic 13
3.6 Deep Deterministic Policy Gradient 15
4 机械臂的测试 19
4.1 二元奖励 19
4.2 奖励塑形 22
4.3 稀疏奖励求解 24
4.4 后见经验回放 25
4.5 层级强化学习 30
4.6 效果展示 32
5 实际应用测试 33
5.1 硬件设计 33
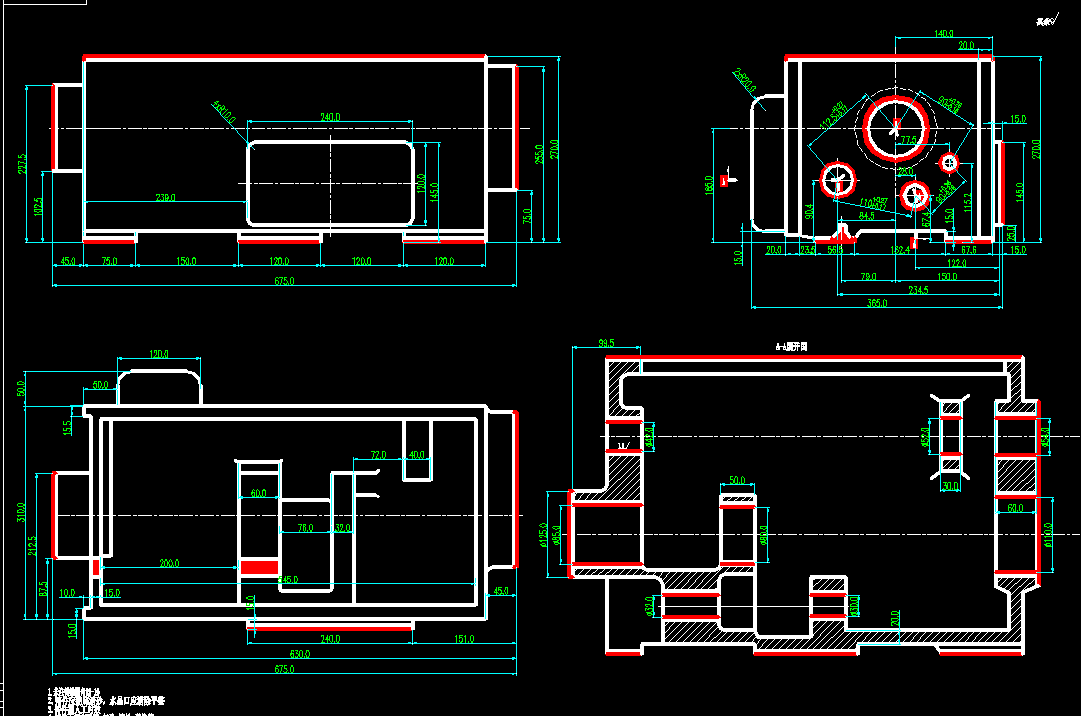
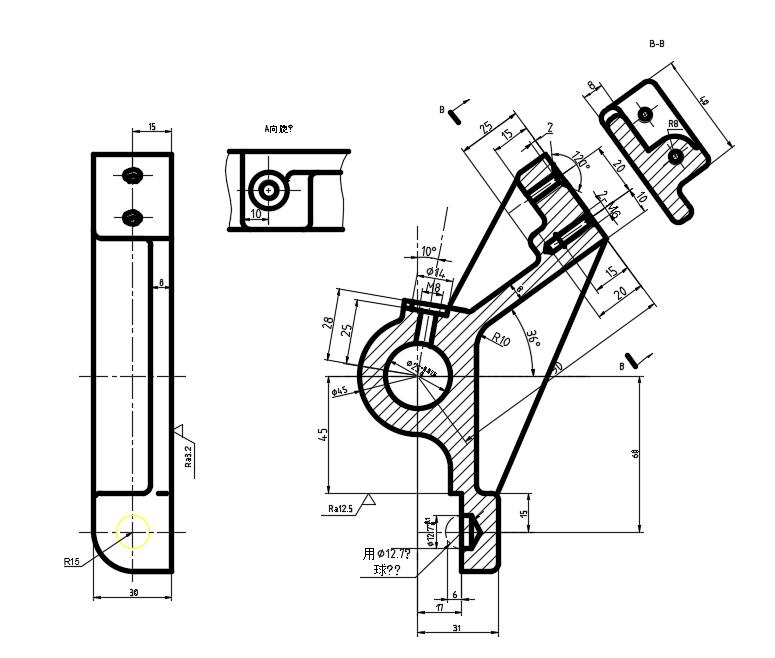
5.1.1 机械臂设计 33
5.1.2 主控电路 33
5.1.3 显示电路 34
5.1.4 供电电路 35
5.1.5 USB转串口电路 36
5.1.6 保护电路 37
5.1.7 蜂鸣器电路 38
5.2 下位机软件设计 39
5.2.1 主程序 39
5.2.2 串口通讯 40
5.2.3 显示器编程 41
5.2.4 警报 42
5.2.5 看门狗 44
5.2.6 RTC时钟 44
5.2.7 下位机完整流程图 44
5.3 上位机软件设计 46
5.3.1通讯建立 46
5.3.2 训练 47
5.3.3 上位机完整流程图 50
5.4 调试结果 51
总结 54
参考文献 55
致谢 57
附录A DDPG训练和测试程序 58
附录B DDPG+HER训练程序 62
附录C 上位机和下位机主程序 65
1 绪论
随着自动化技术的不断发展和广泛的应用,社会生产力得到了空前的发展,不但提高了科技产品的生产速度和生产质量同时也提高了人类的生活质量,也对自动化策略的鲁棒性提出了新的要求。在工业化生产刚刚步入人类社会时,虽然机械被广泛的使用,但是人力依然是生产活动的主力军,这时只要对工人进行不同技能的培训就可以完成不同的生产活动。随着社会的进一步发展,自动化的机器人进入了生产活动中。虽然自动化的机器人提高了生产力,但是另一个问题逐渐暴漏出来,机器人的控制策略往往是基于任务的精确数学模型,这种控制策略虽然可以获得较高的控制精度,但是却失去了一定的自适应性,当生产环境发生了变化,控制策略往往会彻底失效。
随着人工智能的不断发展和应用,这种有着极强自适应性的算法被广泛的应用,例如利用神经网络进行控制[13][14],在部分游戏上人工智能可以说完全战胜了人类,例如传统的打砖头和吃豆人,AI彻的将人类打败,甚至在围棋这种充满了智慧的游戏,人类也被AI完败,这是因为AlphaGo借助计算机,利用蒙特卡洛树搜索和神经网络推算出每一步棋的价值,从而选择最优解。在目标识别领域,人工智能的发展特别的迅速,借助卷积神经网络,例如VGGNet[15]、ResNet[16]、YoLo[17]、SSD[18]、Faster R-CNN[19]等算法出现在世人眼中。当前,神经网络成为了人工智能不可或缺的一部分,从最初的深度神经网络,到现在广泛流行的卷积神经网络和被誉为下一代神经网络的脉冲神经网络[20],再到最新的加法神经网络[21],这些技术的发展会助力社会生产力的进一步提升。将神经网络引入到机械臂的控制中,将会成为一种提高控制效果的方法。
实际上强化学习和深度强化学习已经被应用到了机械臂的控制上[22],例如在机械臂的避障路径规划中使用深度神经网络通过离线学习,就可以使机械臂躲避障碍达到目标点[23];
医用机器人一直是发展的重点之一,由于医用微创手术机器人的特殊性,这要求机器人有着柔顺自然的机械臂动作和交互过程中有着合适的阻尼,利用Sarsa(λ)算法就可以实现这一目标,使机器人有较高的可控性和稳定性[24];在实际的应用场景中,最佳的控制策略往往代表着高效率,通常的强化学习往往学习较慢,而且信息使用率较低,所以基于价值梯度进行实时运动控制的方法被提了出来[25]。
本文在Ubuntu18.04系统下利用python3.6、tensorflow-gpu1.14.0、gym和pyglet等环境构建智能体和测试环境,为了简化实验过程,本文在二自由度机械臂上使用了多种方法对机械臂的控制效果展开了讨论,并且使用了奖励重塑、层次强化学习和事后经验回放加快智能体训练的收敛速度。
参 考 文 献
[1]WATKINS,C. J. C. H. Learning from Delayed Reward[J]. Ph.d.thesis Kings College University of Cambridge, 1989.
[2]Hasselt H V. Double Q-learning[C]. Advances in neural information processing systems. 2010: 2613-2621.
[3]Volodymyr, Mnih, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540):529-533.
[4]Van Hasselt H, Guez A, Silver D. Deep reinforcement learning with double q-learning[C]. Thirtieth AAAI conference on artificial intelligence. 2016.
[5]Wang Z, Schaul T, Hessel M, et al. Dueling network architectures for deep reinforcement learning[J]. arXiv preprint arXiv:1511.06581, 2015.
[6]Sutton R S . Policy gradient methods for reinforcement learning with function approximation[J]. Advances in Neural Information Processing Systems, 2000, 12.
[7]Schulman J, Moritz P, Levine S, et al. High-dimensional continuous control using generalized advantage estimation[J]. arXiv preprint arXiv:1506.02438, 2015.
[8]Wang Z, Bapst V, Heess N, et al. Sample efficient actor-critic with experience replay[J]. arXiv preprint arXiv:1611.01224, 2016.
[9]Haarnoja T, Zhou A, Abbeel P, et al. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor[J]. arXiv preprint arXiv:1801.01290, 2018.
[10] Lillicrap T P , Hunt J J , Pritzel A , et al. Continuous control with deep reinforcement learning[J]. Computer ence, 2015, 8(6):A187.
[11] Andrychowicz M, Wolski F, Ray A, et al. Hindsight experience replay[C]. Advances in neural information processing systems. 2017: 5048-5058.
[12] Nachum O, Gu S S, Lee H, et al. Data-efficient hierarchical reinforcement learning[C]. Advances in Neural Information Processing Systems. 2018: 3303-3313.
[13] 周其节, 徐建闽. 神经网络控制系统的研究与展望[J]. 控制理论与应用, 1992(06):3-11.
[14] Van Rooijen J C, Grondman I , Babu?Ka R . Learning rate free reinforcement learning for real-time motion control using a value-gradient based policy[J]. Mechatronics, 2014, 24(8):966-974.
[15] Simonyan K , Zisserman A . Very Deep Convolutional Networks for Large-Scale Image Recognition[J]. Computer ence, 2014.
[16] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]. Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
[17] Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]. Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 779-788.
[18] Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]. European conference on computer vision. Springer, Cham, 2016: 21-37.
[19] Ren S, He K, Girshick R , et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6):1137-1149.
[20] Ghosh-Dastidar S , Adeli H . SPIKING NEURAL NETWORKS[J]. International Journal of Neural Systems, 2009, 19(04):295-308.
[21] Chen H, Wang Y, Xu C, et al. AdderNet: Do We Really Need Multiplications in Deep Learning?[J]. arXiv: Computer Vision and Pattern Recognition, 2019.
[22] Nageshrao S P , Lopes G A D , Jeltsema D , et al. Passivity-based reinforcement learning control of a 2-DOF manipulator arm[J]. Mechatronics, 2014, 24(8):1001-1007.
[23] 李广创, 程良伦. 基于深度强化学习的机械臂避障路径规划研究%Research on Obstacle Avoidance Path Planning of the Mechanical\r Arm Based on Deep Reinforcement Learning[J]. 软件工程师, 2019, 022(003):12-15.
[24] 杜志江, 王伟, 闫志远, et al. 基于模糊强化学习的微创外科手术机械臂人机交互方法[J]. 机器人, 2017(3).
[25] Hu Y, Si B. A Reinforcement Learning Neural Network for Robotic Manipulator Control[J]. Neural Computation, 2018, 30(7):1983-2004.
[26] Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[J]. arXiv preprint arXiv:1502.03167, 2015.
[27] Pang Z J, Liu R Z, Meng Z Y, et al. On reinforcement learning for full-length game of starcraft[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33: 4691-4698.