


苏ICP备112451047180号-6
基于IBM Modeler的信息分析
摘要:为了能够充分的利用现有资源,实现从海量的数据中获取自己需要的知识内容,数据挖掘这项技术应运而生并充分显示出其强大的生命力。本文主要讲述了数据挖掘技术与web挖掘技术。并使用IBM Modeler软件进行的实例使用。
关键字:数据挖掘技术;IBM Modeler
The information analysis which based on IBM Modeler
Abstract: In order to make full use of existing resources, to achieve access to knowledge content they need from the vast amounts of data, data mining of this technology came into being and fully demonstrated its strong vitality. This paper mainly introduces the technology of data mining and web mining technology. And use the Modeler software to use the example of IBM.
Key words: Data Mining Technology ; I BM Modeler
目录
一、前言 2
二、数据挖掘及其技术 2
(一)数据挖掘概述 2
(二)数据挖掘的演变 2
1.数据挖掘技术的发展 3
2.对数据挖掘的定义 4
(三)web挖掘 4
1.Web结构挖掘 5
2.Web文本挖掘 5
3.Web使用记录挖掘 5
三、IBM Modeler简介及实验分析 6
(一)IBM Modeler软件简介 6
(二)关键方法 6
(三)实验分析 7
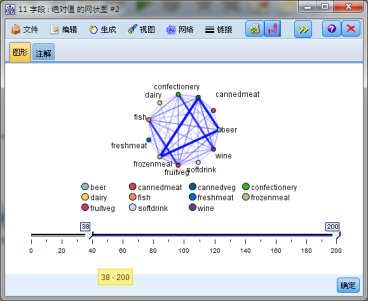
1.关联 7
2.决策树 12
(四)实验结果及分析 19
四、小结 20
五、参考文献 22
现如今,随着海量数据收集的快速增长,人们只是将其存放在大型数据库中,因为缺乏有效的工具,人们的能力已经完全满足不了数据分析的要求,只能将数据置于一处。因此,有人将其称为:“数据坟墓”。
数据搜集工具的进步使人类拥有了庞大的数据量,数据量的急剧增加,人们产生了对新型工具的需求,希望使得这些数据能够以自动化的形式转变为有价值的信息和知识。故而,数据挖掘成为了一个日益受到关注的研究重点区域。
数据挖掘技术是一项能够帮助人们从一堆大量的、毫无张理可言的相关数据集中提取出所需或感兴趣的知识、规律或更高层次的信息的技术,并能够帮助人们以不同的形式、不同的角度、不同的思路来分析这些数据,使人们从这些数据中找出所隐藏且有价值的内容出来。数据挖掘技术不仅仅能够用于描述过去数据的发展过程,而且还能够进一步预测出未来发展的趋势走向。
(1)大容量数据库的出现。大容量的数据库的出现,对数据挖掘技术的发展和普及起到了促进作用。我们能够借助计算机来处理数据,使数据挖掘有了其能赖以生存的环境。
(2)先进计算机技术应用。近些年,网络技术以及并行计算机体系的迅捷发展,使得人类有了更加迅捷的数据把握。也使得人们的视线从搜集数据转换到分析数据,从数据中来找具有重要意义的规律上来。这样子,也使得先进计算机技术应用水平就成为了促进数据挖掘技术发展的一大重要因素。
(3)现代化经营管理的需要。全球性的经济竞争使得企业面临着的压力日趋严重,企业经营管理者想得到整改,就开始对历史数据下手,希望从中找到能解决问题的方法。这就要求有一定的技术支持,以使对企业的数据进行挖掘。
(4)对数据挖掘有更深层、深精度的要求。对数据挖掘精、深能力的要求,势必是要涉及到关于信息论、统计学、人工智能、集合论等相关文学的理论和技术。[1]
因此,可以这么说,数据挖掘技术是心急技术发展到一定程度的必然会有的结果。
数据挖掘技术其实是一个逐渐完善的演变过程。人们从一开始进行的机器学习到后来的重点—知识工程,到了20世纪80年代,又重新将目光注视到机器学习中,这一项研究成果被应用在大型商业数据库中,并产生了一个新的术语—数据库中的知识发现,也就是KDD。
KDD(Knowledge Discovery in Database)泛指所有能够从源数据中发掘模式或联系的方法,是从数据集中识别出新颖的、、可获取的、有效的、潜在有用的,以及最终可理解的模式的过程。常用来描述整个数据发掘的过程,近几年,数据挖掘中有许多工作逐渐开始使用统计方法来完成,并将统计方法和数据挖掘有机的结合起来。[2]
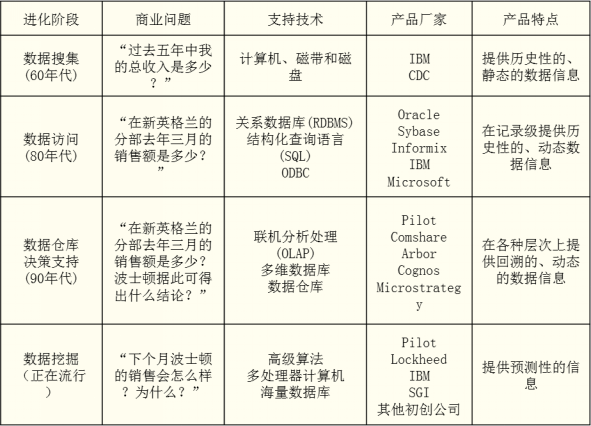
在商业数据库以前所未有的速度增长,进一步加快了数据挖掘走向完善的步伐。不同的角度,能发现的也不同,当我们以用户的角度来看待时,可以发现——数据库技术已经能够很完善且快速的回答许多商业上的问题了。表1已经总结了数据挖掘的演变过程。
通过一系列技术的应用,使得数据挖掘能作为知识发现,即KDD过程的一个特定的步骤,或者说是大数据。
Web挖掘从数据挖掘而来,定义与数据挖掘类似,但却与数据挖掘有着许多的不同之处。
首先,传统数据不再是web数据挖掘的重点,其重点是大量的web文件。而因为是以web作为媒介对数据库进行的挖掘,所以这一点上和传统挖掘是一致的。
其次,因为不是传统数据,而是在逻辑上是由文件节点和超链接构建而成的图形样式的web信息,因此,web挖掘所得到的结果可能是关于web内容的,也可能是关于web结构的。
此外,新的web挖掘技术,能够成为web挖掘研究的重点是由于web文件其本身是半结构或者无结构的,缺乏机器语言。故一些现有的挖掘工具难以对web进行挖掘。
Web结构挖掘、Web文本挖掘和Web使用记录挖掘这三种类型,就是依据在挖掘过程中使用的数据类别划分出的三种主要类型。
[2] 谭华 著. 基于遗传神经网络的CRM市场营销数据挖掘模型的研究[D]. 广西:广西大学,2003
[3] 刘涛 雪亮 著. 数据挖掘在企业决策中的应用[D]. 北京:北京科技大学,2008
[4] 高英明 著. 数据挖掘与知识发现(DMKD)及其应用的研究[D] 北京:华北电力(北京)大学,2002
[5] 黄鲁成 杨少娣 著. 论Web挖掘在新兴技术产业化潜力评估中的应用[D]. 经济论坛,2009
[6] 毛慧燕 著. 关联规则挖掘相关算法研究[D]. 武汉大学 2011
[7] 文安邦 著. 基于网络流量日志的分析与安全审计[D]. 大连海事大学 2010
[8] 包淑玮 胡军国 著. 基于数据库技术的Apriori改进算法研究与应用[D]. 浙江:浙江农业大学,2013.
[9] 梁丽琴 著. 虚占时刻航班异常延误行为研究[D]. 电子科技大学,2009
摘要:为了能够充分的利用现有资源,实现从海量的数据中获取自己需要的知识内容,数据挖掘这项技术应运而生并充分显示出其强大的生命力。本文主要讲述了数据挖掘技术与web挖掘技术。并使用IBM Modeler软件进行的实例使用。
关键字:数据挖掘技术;IBM Modeler
The information analysis which based on IBM Modeler
Abstract: In order to make full use of existing resources, to achieve access to knowledge content they need from the vast amounts of data, data mining of this technology came into being and fully demonstrated its strong vitality. This paper mainly introduces the technology of data mining and web mining technology. And use the Modeler software to use the example of IBM.
Key words: Data Mining Technology ; I BM Modeler
目录
一、前言 2
二、数据挖掘及其技术 2
(一)数据挖掘概述 2
(二)数据挖掘的演变 2
1.数据挖掘技术的发展 3
2.对数据挖掘的定义 4
(三)web挖掘 4
1.Web结构挖掘 5
2.Web文本挖掘 5
3.Web使用记录挖掘 5
三、IBM Modeler简介及实验分析 6
(一)IBM Modeler软件简介 6
(二)关键方法 6
(三)实验分析 7
1.关联 7
2.决策树 12
(四)实验结果及分析 19
四、小结 20
五、参考文献 22
一、前言
在以计算机和网络为代表的信息技术的发展的今天,愈来愈多的企业、教育机构和科研单位已然成功实现了信息的数字化处理工作。数据库,特别是数据仓库已经被广泛地应用到企业管理、信息服务、产品销售和科学计算等多个领域。同时,随着大数据库的建立和海量数据的不断涌现,必然提出对强有力的数据分析工具的迫切需求。但现实情况往往是“数据十分丰富,而信息相当贫乏。现如今,随着海量数据收集的快速增长,人们只是将其存放在大型数据库中,因为缺乏有效的工具,人们的能力已经完全满足不了数据分析的要求,只能将数据置于一处。因此,有人将其称为:“数据坟墓”。
数据搜集工具的进步使人类拥有了庞大的数据量,数据量的急剧增加,人们产生了对新型工具的需求,希望使得这些数据能够以自动化的形式转变为有价值的信息和知识。故而,数据挖掘成为了一个日益受到关注的研究重点区域。
二、数据挖掘及其技术
(一)数据挖掘概述
数据挖掘技术是一项人们通过长期进行的对数据库技术进行的研究和开发的结果的展示。人们通过人工智能的学习、结合产生了数据挖掘与其衍生出的知识。而在二十世纪末时,数据挖掘就已经有了很大的进步。而发展到现在,数据挖掘技术已经不仅仅只是一项研究。而是已经在众多领域,比如:市场分析、医疗卫生、政府管理、金融、制造业及科学探索等都得到了应用并取得了一定的实效的技术了。数据挖掘技术是一项能够帮助人们从一堆大量的、毫无张理可言的相关数据集中提取出所需或感兴趣的知识、规律或更高层次的信息的技术,并能够帮助人们以不同的形式、不同的角度、不同的思路来分析这些数据,使人们从这些数据中找出所隐藏且有价值的内容出来。数据挖掘技术不仅仅能够用于描述过去数据的发展过程,而且还能够进一步预测出未来发展的趋势走向。
(二)数据挖掘的演变
1989年,在第11届国际人工智能联合会议的专题讨论会上,数据库的知识发现(Knowledge Discovery in Database , KDD)技术。到了1995年,在美国计算机年会(ACM)上提出了数据挖掘的概念。1.数据挖掘技术的发展
数据挖掘技术的产生可以说是以下四大方面促成的:(1)大容量数据库的出现。大容量的数据库的出现,对数据挖掘技术的发展和普及起到了促进作用。我们能够借助计算机来处理数据,使数据挖掘有了其能赖以生存的环境。
(2)先进计算机技术应用。近些年,网络技术以及并行计算机体系的迅捷发展,使得人类有了更加迅捷的数据把握。也使得人们的视线从搜集数据转换到分析数据,从数据中来找具有重要意义的规律上来。这样子,也使得先进计算机技术应用水平就成为了促进数据挖掘技术发展的一大重要因素。
(3)现代化经营管理的需要。全球性的经济竞争使得企业面临着的压力日趋严重,企业经营管理者想得到整改,就开始对历史数据下手,希望从中找到能解决问题的方法。这就要求有一定的技术支持,以使对企业的数据进行挖掘。
(4)对数据挖掘有更深层、深精度的要求。对数据挖掘精、深能力的要求,势必是要涉及到关于信息论、统计学、人工智能、集合论等相关文学的理论和技术。[1]
因此,可以这么说,数据挖掘技术是心急技术发展到一定程度的必然会有的结果。
数据挖掘技术其实是一个逐渐完善的演变过程。人们从一开始进行的机器学习到后来的重点—知识工程,到了20世纪80年代,又重新将目光注视到机器学习中,这一项研究成果被应用在大型商业数据库中,并产生了一个新的术语—数据库中的知识发现,也就是KDD。
KDD(Knowledge Discovery in Database)泛指所有能够从源数据中发掘模式或联系的方法,是从数据集中识别出新颖的、、可获取的、有效的、潜在有用的,以及最终可理解的模式的过程。常用来描述整个数据发掘的过程,近几年,数据挖掘中有许多工作逐渐开始使用统计方法来完成,并将统计方法和数据挖掘有机的结合起来。[2]
在商业数据库以前所未有的速度增长,进一步加快了数据挖掘走向完善的步伐。不同的角度,能发现的也不同,当我们以用户的角度来看待时,可以发现——数据库技术已经能够很完善且快速的回答许多商业上的问题了。表1已经总结了数据挖掘的演变过程。
2.对数据挖掘的定义
(1)技术层次上的定义
数据挖掘就是应用一系列技术从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们感兴趣的信息和知识,这些内容是隐含的、未知而蕴有内涵的,其提取的知识可以是概念、模式、规律等形式。[3]通过一系列技术的应用,使得数据挖掘能作为知识发现,即KDD过程的一个特定的步骤,或者说是大数据。
(2)商业层次上的定义
从商业角度来看,数据挖掘是一种新的商业信息处理技术。其主要技术特点是能够分析商业数据库中的大量业务数据,并对这些数据进行转换、抽取、分析和其他模型化处理,帮助决策者寻找数据间潜在的关联,寻找到被忽略的因素。[4](三)web挖掘
Web挖掘是数据挖掘在Web上的应用,Web作为一项涉及Web技术、计算机语言学、数据挖掘、信息学等多个领域的综合技术,能够利用数据挖掘技术从与WWW相关的资源和行为中抽取感兴趣的、有用的模式和隐含信息。Web挖掘从数据挖掘而来,定义与数据挖掘类似,但却与数据挖掘有着许多的不同之处。
首先,传统数据不再是web数据挖掘的重点,其重点是大量的web文件。而因为是以web作为媒介对数据库进行的挖掘,所以这一点上和传统挖掘是一致的。
其次,因为不是传统数据,而是在逻辑上是由文件节点和超链接构建而成的图形样式的web信息,因此,web挖掘所得到的结果可能是关于web内容的,也可能是关于web结构的。
此外,新的web挖掘技术,能够成为web挖掘研究的重点是由于web文件其本身是半结构或者无结构的,缺乏机器语言。故一些现有的挖掘工具难以对web进行挖掘。
Web结构挖掘、Web文本挖掘和Web使用记录挖掘这三种类型,就是依据在挖掘过程中使用的数据类别划分出的三种主要类型。
1.Web结构挖掘
Web结构挖掘是从表征Web结构的超链接(简称链接)中推导知识。Web结构挖掘的目的就在于找出蕴含在web文件结构信息中的有用模式。2.Web文本挖掘
Web 文本挖掘能够对Web 上的大量文档的集合的内容进行总结、分类、聚类、关联分析,以及利用Web 文档进行趋势预测。在互联网上的文本数据通常是一组html 格式的文件,要将这些文件转化成一种相似关系数据库中记录的规整且能反映文件内容特征的表示,一般采用文档特征向量,但眼下所采用的文档表示方法中,都存在一个弊端就是文档特征向量具有很大的维数,使得特征子集的选取成为Internet 上文本数据挖掘过程中的不可缺少的一个环节。[5]3.Web使用记录挖掘
Web使用记录挖掘,指的是挖掘Web日志中用户的网页访问的模式。通过Web日志记录中的规律的分析和研究,以识别电子商务的潜在客户;可以用于基于扩展有向树模型来识别用户的浏览模式,而Web日志挖掘;用户可以根据兴趣关联规则的用户访问网站的记录,存放在知识库中的利益关联,为据预测用户的行为,用户需要预先一些页面,加快用户获取页面的速度参考文献
[1] 康晓东 著. 基于数据仓库的数据挖掘技术[M]. 北京:机械工业出版社,2004.[2] 谭华 著. 基于遗传神经网络的CRM市场营销数据挖掘模型的研究[D]. 广西:广西大学,2003
[3] 刘涛 雪亮 著. 数据挖掘在企业决策中的应用[D]. 北京:北京科技大学,2008
[4] 高英明 著. 数据挖掘与知识发现(DMKD)及其应用的研究[D] 北京:华北电力(北京)大学,2002
[5] 黄鲁成 杨少娣 著. 论Web挖掘在新兴技术产业化潜力评估中的应用[D]. 经济论坛,2009
[6] 毛慧燕 著. 关联规则挖掘相关算法研究[D]. 武汉大学 2011
[7] 文安邦 著. 基于网络流量日志的分析与安全审计[D]. 大连海事大学 2010
[8] 包淑玮 胡军国 著. 基于数据库技术的Apriori改进算法研究与应用[D]. 浙江:浙江农业大学,2013.
[9] 梁丽琴 著. 虚占时刻航班异常延误行为研究[D]. 电子科技大学,2009