


苏ICP备112451047180号-6
基于矩阵分解的协同过滤推荐算法研究
摘要
本文主要研究基于矩阵分解的协同过滤推荐算法。第一章介绍了研究的背景和意义,以及当前研究的现状,包括基于内存和模型的协同过滤推荐算法。第二章对协同过滤推荐进行了概述,包括基于用户和基于项目的协同过滤推荐,以及传统SVD和FunkSVD推荐算法。第三章提出了基于归一化最小均方的矩阵分解协同过滤推荐算法,并进行了仿真实验。第四章提出了基于最大相关熵准则的矩阵分解协同过滤推荐算法,并进行了仿真实验。第五章提出了基于自适应矩估计优化的矩阵分解协同过滤推荐算法,并进行了仿真实验。最后一章总结了全文的研究成果,并对未来的研究方向进行了展望。
目录
第一章 绪论 3
1.1 研究背景与意义 3
1.2 研究现状 4
1.2.1 基于内存的协同过滤推荐 4
1.2.2 基于模型的协同过滤推荐 5
1.3 本文研究内容与行文结构 7
1.3.1 本文研究内容 7
1.3.2 本文行文结构 8
第二章 协同过滤推荐概述 11
2.1 基于内存的协同过滤推荐 11
2.1.1 基于用户的协同过滤推荐 11
2.1.2 基于项目的协同过滤推荐 12
2.2 基于模型的协同过滤推荐 13
2.2.1 传统SVD推荐算法 14
2.2.2 FunkSVD推荐算法 14
2.3 本章小结 17
第三章 基于归一化最小均方的矩阵分解协同过滤推荐 19
3.1 归一化最小均方算法概述 19
3.2 基于归一化最小均方的矩阵分解协同过滤推荐算法 20
3.3 仿真结果 23
3.3.1 面向MovieLens100K数据库 23
3.3.2 面向景点数据 25
3.4 本章小结 28
第四章 基于最大相关熵准则的矩阵分解协同过滤推荐 29
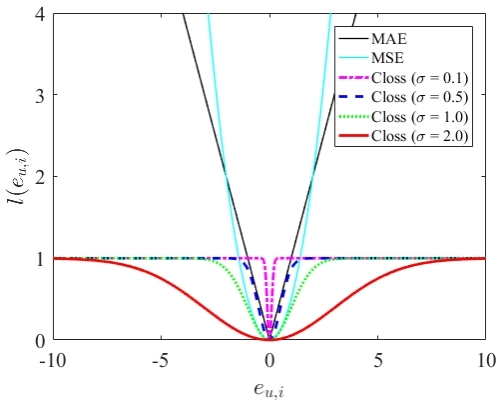
4.1 相关熵损失函数 29
4.2 基于最大相关熵准则的矩阵分解协同过滤推荐 31
4.3 仿真结果 34
4.3.1 面向MovieLens100K数据库 35
4.3.2 面向景点数据 37
4.4 本章小结 39
第五章 基于自适应矩估计优化的矩阵分解协同过滤推荐 41
5.1 SGD优化改进方法概述 41
5.2 基于自适应矩估计优化的矩阵分解协同过滤推荐 43
5.3 仿真结果 46
5.3.1 面向MovieLens100K数据库 46
5.3.2 面向景点数据 47
5.4 本章小结 48
第六章 结论与展望 49
6.1 结论 49
6.2 展望 50
第一章 绪论
1.1 研究背景与意义
在当今这个网络大发展的时代,随时随地了解世界各地发生的大事小情,获取各个行业的相关信息,与天南海北的朋友交流,都不再是难事。随着自媒体时代的到来,每个人不仅是信息的接收者与传输者,也是信息的生产与发布者。随之而来的便是信息的指数级增长,人们的需求日益多样化、个性化。如何快速、准确地从海量、过载的信息中得到个人切实所需,成为了又一现实问题。
随着人们生活水平的提高与消费习惯的改变,网上购物、线上服务等成为了大家热衷的生活方式。不再仅仅是有目的地检索,很多时候是无目的地浏览, 更复杂的情况是人们有时候根本不知道自己想要的是什么。于是,推荐系统便应运而生。各大商业网站、平台牢牢抓住这一契机,积极地加入到了推荐系统落地的行业中。许多商家希望把网站的浏览者变为商品的购买者,这些商品包括新闻、书籍、电影、音乐、旅游规划等。通过分析用户的历史点击、评论、评分等信息,为用户提供个性化推荐服务,成为了研究的主要思路。美国著名的线上电影服务平台——Netflix为提高推荐系统的准确度和用户满意度,2006年发布了1亿条匿名电影评分数据,并悬赏100万美元作为奖励,希望能够有更多更好的算法被提出。一时间,推荐算法引起了国内外广泛的关注。电子商务如Amazon、eBay、Alibaba,电影网站如MoviesLens、Netflix、Moviefinder,都是典型的推荐系统。
推荐算法是推荐系统的核心,算法性能的优劣决定了推荐系统的成败。由于协同过滤推荐算法具有简单、可解释性的特点,成为了目前最流行的推荐算法之一。较早的协同过滤推荐算法是基于用户或项目分析用户与用户或项目与项目之间的相似程度为目标用户做推荐。考虑到用户兴趣会随着时间的变化而发生或多或少的改变,为提高预测准确度和用户满意度,时间因素被加入计算。2006年后,矩阵分解技术被大量应用到推荐系统中,为处理传统协同过滤算法中无法较好解决的数据稀疏性问题提供了很好的方法。矩阵分解挖掘隐藏的用户或项目特征,拥有更好的预测效果,而且能够同时应用于离线和在线推荐中。因此,研究基于矩阵分解的推荐算法具有实用价值。在传统的基于矩阵分解的CF推荐算法中,没有考虑到用户特征向量和项目特征向量的能量(方差)对算法推荐性能和稳定性的影响。此外,这些传统的推荐算法均是基于均方误差(MSE, mean square error)损失函数设计的,因此不具备应对异常干扰的鲁棒性。再者,绝大多数推荐算法是利用随机梯度下降(SGD, stochastic gradient descend)优化方法建立的,由于SGD方法在最优解附近来回振荡,从而导致较差的推荐性能和收敛速度。因此,建立能够应对各种能量的用户和项目特征向量、对抗异常干扰、提高推荐性能和加快收敛速度的高效CF推荐算法,同样具有现实应用价值。
综上,本文将从应对不同能量的用户和项目向量、对抗推荐系统中存在的异常干扰、以及提高推荐性能和收敛速度的角度对基于传统矩阵分解CF推荐算法进行改进,进而提出高效的推荐算法,因此,本文研究的算法在理论上和实践应用中均具有一定的价值与意义。
1.2 研究现状
1.2.1基于内存的协同过滤推荐
基于内存的协同过滤推荐分为基于项目的协同过滤推荐和基于用户的协同过滤推荐,此类算法以行为或特征相似的“用户-用户”或“项目-项目”之间的相似关系为核心,以此过滤出用户的兴趣偏好[1]。基于用户的CF的基本思想是从历史用户集中识别出新用户的前n个最相似的邻居用户,将前n个邻居用户的项目偏好用于对新用户的推荐[2]。不同于基于用户的CF,基于项目的CF首先基于共享用户建立项目相似性度量,且在许多应用中项目数量通常远小于用户数量。因此,基于用户的CF存在巨大的计算成本问题,基于项目的CF被提出用以大规模用户-项目数据[3]。
基于“用户-用户”的算法和基于“项目-项目”的算法最大的区分在于被计算相似度的对象不同。前者需要计算的是用户与用户之间的相似度,而后者计算的则是项目与项目之间的相似度。基于这两类算法设计的推荐系统均存在一个相同的问题,即冷启动问题。对于基于“用户-用户”的协同过滤推荐系统中的新用户来说,由于系统中缺少该用户的历史记录,无法为其匹配到相似用户,推荐算法也因此无法正常计算。在基于“项目-项目”的协同过滤推荐系统中每增加一个新的项目,由于新项目不存在评分度量,同样也无法匹配到其余的相似项目,故推荐系统无法启动。为解决冷启动问题,目前已有不少解决方案,通常的做法有两类:一类是通过聚类的方法根据属性相似性对用户或项目进行聚类,以便匹配相似的对象[4-7],另一类是利用多源社交网络中的社会关系,基于信任传播机制,根据组合已有评分信息用户的评分结果,给无评分信息的用户推荐项目[8-10]。
基于用户的协同过滤是最早的推荐算法。该算法在1992年被提出,用于邮件过滤系统,后又被用于新闻过滤。为了解决传统算法可扩展性差的问题,Zhi-Dan Zhao和Ming-Sheng Shang[11]在云计算平台Hadoop上实现基于用户的协同过滤算法,该算法基于一定的原则,将用户划分为不同的群组。苏林宇、陈学斌[12]通过建立“项目-用户”倒查表计算用户评分矩阵,“惩罚”用户共同兴趣列表中的热门项目,改进基于用户的协同过滤算法,通过十折交叉方法做出验证。 2018年,陈旭[13]在其论文中采用基于用户的协同过滤算法挖掘出与用户要求最为相似的前n条旅游线路,综合景点类型、用户偏好以及路线流行度等因素进行推荐。
基于项目的协同过滤因其计算成本较基于用户的低,是目前工业界应用最广泛的邻域算法。2001年,Badrul Sarwar[3]等人利用改进的余弦相似性算法进行项目间相似性度量,预测精度高于传统的基于用户的k最近邻算法。Xiangnan He[14]等人认为在预测用户对某一item的得分时,历史数据应该有不同的影响程度,不能同等视之,于是提出在FISM(Factored Item Similarity Model)的基础上,利用神经网络学习得到各项历史item的权重系数,进而对项目评分。Taolin Guo[15]等人提出基于项目的局部差异隐私协同过滤框架,在服务器端重构相似性度量,保证推荐准确度的同时降低用户历史信息泄露的危险。
1.2.2基于模型的协同过滤推荐
基于模型的协同过滤推荐算法有很多,如矩阵分解、聚类模型、图模型等,以下是具体的介绍。
矩阵分解是将一个高维矩阵空间分解为两个或多个低维矩阵空间内积的算法,用于发掘用户、项目的隐含特征。传统矩阵分解主要有奇异值分解、概率矩阵分解、非负矩阵分解和贝叶斯概率矩阵分解。2005年,Sheng Zhang[16]等人在求取期望最大化的过程中利用奇异分解技术(SVD),在保证预测精度的情况下降低了全局计算的时间消耗,并且保护了用户评分隐私信息。自2006年Netfilx开始举办旨在促进推荐系统发展的The Netflix Prize比赛后,矩阵分解技术获得了巨大的成功[17-18]。2009年,The Netflix Prize的排名第一的获奖团队[19]在其发表的文章中概述了推荐系统,重点讲解了矩阵分解(MF)技术、学习算法(随机梯度下降、交替最小二乘)、偏置改进,以及随时间变化的算法优化。早期的矩阵分解算法[20]主要集中在直接反馈信息(如用户项目评分)的研究上,将推荐问题转化为用户对未评分项目的评分预测问题。这样极大地降低了用户偏好建模的工作负担,有许多较为复杂的算法也随之被提出,如SVD++[21]、timeSVD[22]。在2016版的《个性化推荐算法与优化》一书中,张志军[23]做了大量相关研究:基于概率矩阵分解算法(PMF),考虑到用户兴趣会随着时间的变化而变化这一规律,提出融合时间效应的矩阵分解算法(TPMF),并在实验中验证了这一算法较PMF优越;为解决传统协同过滤算法中存在的冷启动问题,利用社交媒体数据,分析用户间的直接与间接关系,建立基于信任机制的推荐模型(CETrust);将时间序列、CETrust、评分矩阵融合到概率矩阵中,提出了一种新的个性化推荐方法——TrustSeqMF;运用位置信息、时间因素、社交网络中的信任关系,研究人们活动的动态规律,提出一种移动网络下融合上下文信息的用户社交关系的推荐算法,提高了推荐结果的准确性和用户满意度。虽然推荐算法中采用的数据绝大多数为用户评分数据,但由于该数据具有很高的稀疏性,有时并不能取得较好的预测效果。于是,点击流数据、购买历史、检索历史等这些隐含了用户偏好的信息便被提取出来用于推荐算法中。Jiro Iwanaga[24]等人通过用户点击的历史页面记录,根据点击时间、点击频率估计项目被选择的概率,实现了小样本数据也能获得较好的推荐性能。涂丹丹[25]为保障广告投放商的利益,与取得更好的用户满意度,基于联合概率矩阵分解模型,综合用户历史点击信息、广告、网页内容这三个方面,为用户推荐合适的广告。由于非负矩阵分解算法有着快速的收敛速度以及所需存储空间很小的特点,被应用到了图像、音频、文本处理等领域。Tao Li[26]基于非负矩阵分解和随机扰动技术的混合算法,解决云计算推荐过程中的用户隐私保护问题。黄波[27]利用非负矩阵分解强大的解释能力,揭示用户与物品之间的隐藏关系,基于用户、项目的协同过滤算法进行个性化推荐。Xiang Wangp[28]制定了跨域社交推荐任务,通过结合信息平台与社交平台中共有用户的感兴趣项目和信任关系传递机制,将Trip.com上的项目推荐给社交平台(Facebook、Twitter)上的用户。传统的基于模型的CF算法中采用指数函数、自然指数函数或分段函数作为其学习率函数[29]。近期的文章[30]提出了一种将指数函数与线性函数相结合的新型自适应学习率(ALR)函数,对SVD++算法进行改进,在训练大样本数据时,在不牺牲推荐性能的情况下减少了迭代次数与训练时间。
聚类技术是数据挖掘中进行数据处理的重要分析工具和方法,它是将物理或抽象的数据对象按照对象间的相似性进行分组或分类的过程。R. Logesh [31]提出BICE(bio-inspired clustering ensemble,生物启发聚类集成)模型,该模型集合了K-PSO(Particle Swarm Optimization)、FCM-PSO(fuzzy C-mean)和K-MWO(Mussels Wandering Optimizations)进行高效的、基于用户的聚类,并从精度、召回率、稳定性等方面与其他聚类方法对比,取得了较好的效果。Mingyang Jiang[32]运用双边聚类和信息熵方法解决了传统协同过滤算法存在的数据稀疏化问题和深度学习方法中普遍存在的高计算消耗问题,在拥有较好准确率的同时降低了时间成本。Jiangzhou Deng[33]等人从项目的评分概率分布角度出发,考虑到不同项目拥有不同数量的评分,提出非对称的距离度量方式,基于Kullback–Leibler散度,充分利用评分信息,在选择聚类中心时高效地划分不同项目,从而提高了预测精度。2019年,HANGYU YAN[34]等人使用高斯混合模型分别对用户与项目进行聚类,然后将经过了Triangle改进的Jaccard方法用于用户、项目相似性度量,既解决了数据的稀疏性问题,又提高了预测的准确度。
图模型是将数据用图的形式表示出来,在图中用户、物品用点表示,用户与物品的连线表示交互或相似性[35]。为解决传统协同过滤算法中普遍存在的冷启动问题,张超[36]在用户-产品二部图的基础上添加标签项,提出一种基于加权三部图网络的协同过滤算法,提高了推荐精度。Maryam Khanian Najafabadi[37]结合Google搜索引擎采用的著名图模型方法PageRank和协同过滤技术,从用户活动的时间信息和项目相关性中找到链式反应规律。孟桓羽[38]等人基于图模型改进kNN算法,提出GK-CF方法,利用图的消息传递能力,对基础算法进行了并行化实现及优化。
1.3 本文研究内容与行文结构
1.3.1本文研究内容
通过前期对基于内存的CF推荐算法和基于模型的CF推荐算法的研究文献发现,基于模型的CF推荐算法相对于基于内存的CF推荐算法在应对冷启动问题、数据稀疏性问题和在线推荐应用问题方面存在优势。因此,本文的研究重点是基于模型的CF推荐算法。通过整理发现,目前在基于模型的CF推荐算法方面的研究存在以下三个方面的问题:
(1)基于SVD矩阵分解的推荐算法如何应对大能量(通常指方差)用户特征向量和项目特征向量引起的稳定性问题;
(2)基于SVD矩阵分解的推荐算法如何应对系统异常干扰引起的算法无法收敛的问题;
(3)基于SVD矩阵分解的推荐算法如何通过设计新型算法进一步提高其推荐性能的问题。
针对以上三个问题,本文将从提高基于SVD矩阵分解的推荐算法的鲁棒性和推荐性能出发对传统的SVD推荐算法进行优化,从而提出改进的基于SVD矩阵分解的CF推荐算法。本文的主要研究内容如图1.1所示,主要包括三个方面的研究内容,即基于归一化方法的矩阵分解推荐、基于最大相关熵损失函数的矩阵分解推荐和基于Adam优化方法的矩阵分解推荐。本文从归一化、损失函数和优化方法三个方面对传统基于SVD矩阵分解的推荐算法进行改进,提出新型的基于矩阵分解的CF推荐算法,并通过标准的MovieLens数据库对提出的算法进行有效性验证,进一步面向景点数据做推荐。
1.3.2本文行文结构
本文的行文结构如下:
第一章,阐述推荐系统与协同过滤算法产生的背景与本研究的意义,总览了基于内存、基于模型的协同过滤算法的国内外研究现状,引出其中存在的问题与拟采取的解决方案。
第二章,分别对基于用户的CF推荐和基于项目的CF推荐进行了概述,并阐述了它们在冷启动和数据稀疏性方面存在的问题。接着,分别介绍了基于矩阵分解的传统SVD推荐算法和FunkSVD推荐算法。最后引出传统基于矩阵分解的CF推荐算法存在的问题。
第三章,首先引出传统基于SVD矩阵分解的推荐算法在数据能量较大时存在的稳定性问题,并介绍了常用于解决稳定性的归一化方法。然后,利用归一化方法,提出了NLMS-MF算法。最后,利用MovieLens数据库和景区数据对NLMS-MF算法的有效性进行验证。
第四章,首先阐述传统基于MSE损失函数的推荐算法不具备应对脉冲干扰的鲁棒性的问题,介绍了相关熵及其在鲁棒学习算法中的应用。然后,利用Closs函数替换MSE损失函数并利用SGA方法对其进行优化,提出了MCC-MF算法。最后,在脉冲干扰环境,利用MovieLens数据库和景区数据对MCC-MF算法的鲁棒性进行验证。
第五章,首先介绍了机器学习中常应用的改进的SGD优化方法及其特点,重点介绍了Adam优化方法及其应用。然后,将Adam优化方法应用于矩阵分解CF推荐,提出了Adam-MF推荐算法。最后,分别在MovieLens数据库和景区数据集上的仿真验证了Adam-MF算法相对于传统算法的优越性。
第六章,对本文的研究内容进行全方位的总结,并结合现有的研究基础与条件,提出几点未来研究的思路。