

��ICP��112451047180��-6
Web��������ķ��������
ժ Ҫ
���Ż������IJ��Ϸ�չ�������ռ������ϵ���Ϣ���ڱ�ըʽ��������������ʱ�����ҵ���������Ҫ�����Ͼͳ���һ���dz��ؼ������⡣Ϊ�˽��������⣬Web�����������֮�����ˣ����õ��˷��ٷ�չ�������Ѿ���Ϊ�������Ͻ����ڵ����ʼ��ĵڶ����������
���ȣ����Ľ�����Web�����������ʷ����״��
��Σ����Ľ�����Web��������Ļ���ԭ���ͼ�����
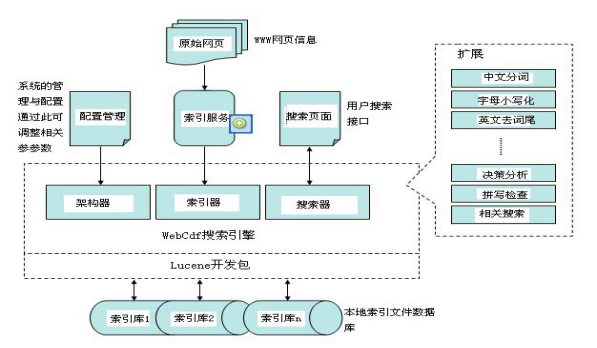
�ٴΣ����ķ�����Web���������ϵͳ�ṹ�������ش�����֩�룬���������Web��ѯ�����������ֽ�������ϸ�����������ͬʱ��������������Java���������£�������ʵ��һ�����ÿ�Դ���߰���Web��������——WebCdf������Web��Ϣ�Ѽ�������WebSpider��Web��ѯ������Search������ϵͳ��
WebCdf���������ָ����Webҳ�濪ʼ�������ѻ�õ����ӷ��빤�����У�����ά���Ͻ��й����������������ÿ��ҳ���URL��ַ���ı����������������ݿ⣬Ȼ��Web���������տͻ����������ݿ��з���ҳ����Ϣ��
���Ľ��ܺ��о���һϵ����Web����������صļ�����������ҳץȡ�����������VSM������Ϣ��ȡ����Ϣ�����ȣ���Щ��������Ӧ�õ����������ϵͳ��Ʒ����С�
����ļؽ��������������δ����չ���ơ�
�ؼ���: ���������������棬��Ϣ��ȡ��Java
Web���������ԭ������
3.1 ����ԭ��
��������Ļ���ԭ����ͨ������֩�붨����web��ҳ�����У�Ȼ�����µ���ҳ��������ȡ�����ŵ����ص����ݿ��У��û��IJ�ѯ�������ͨ����ѯ���ص����ݿ����õ���
��������������֩���Զ�����ҳ�ϰ�ij�ֲ��Խ���Զ�����ݵ��������ȡ�������ɱ������������ڲ���Ҫ���ǵĽ��룬�ٶȵ��Լ������ߡ��串����ͼ�ʱ��Ҳ���Դ�����ߡ�Spider����WWW�ļ����������������Σ���¼ URL���ļ��ļ���ժҪ���ؼ��ֻ��������γ�һ���ܴ�����ݿ⣬�������ݿ�������⡢ժҪ���ؼ��ʺ�URL���ļ��Ĵ�С�������Լ��ʳ��ֵ�Ƶ�ʡ��������з�ʽΪ����һ����һ��URL��ʼ�����ʸ�URL��ָHTML�ļ������е�URLê����Ȼ��������Щ�µ�URLΪ��ʼ�㣬�������б���������ֱ����Ҳû�������������µ�URL Ϊֹ���ڼ�¼�µ�URLʱ�����Խ��з������жϣ�����ȥ������Ҫ����Ҫ��URL���ⲻ������˱����������ٶȣ�Ҳ�����������ļ��ڱ�����ռ�õĴ��̿ռ䡣
�������潫HTML ��ʽ�ļ�ȡ�����غ���һ��С�������еĸ�������ȥ���������HTML��ǩ���ű�������һ�����Խ����п����ڲ�ѯ�IJ��� (��ؼ��ֺ�һЩָ���ʵ� )�洢�����ݿ��У��γɱ��ز�ѯ���ݿ⣬�Ժ��ٲ�ʱ�Ͳ��ص�Զ��ȥ���»�ȡHTML ��ʽ�ļ��� ��
���û�����ؼ��ʣ�Keyword����ѯʱ�����������������û������ùؼ�����Ϣ��������ַ�����ṩͨ�����������ӡ�������������ݼ�����ʽ��Ҫ�ǹؼ��ֵ�ƥ�䷽ʽ���緺ƥ�䡢ģ��ƥ�䡢����ƥ���Լ���ؼ��ֵĴ�����ʽ�� ����Ϊ�û��ṩȫ��������Լ���Լ��������ڲ�����ϵ�IJ�ѯ��ʽ�����Բ�ѯ�������ij���㷨�������ֺ�����
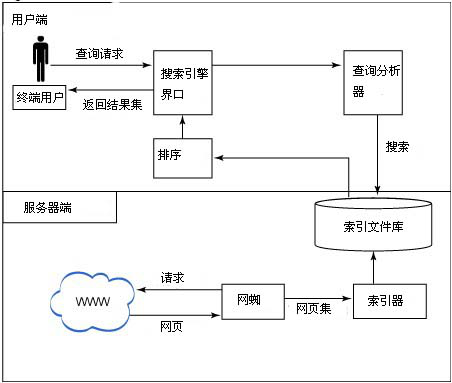
ͨ��һ�� Web��������ļܹ�[7]��Ϊǰ�˺ͺ�������֣�����ͼ2-2����ʾ����ǰ�������У��û������������ṩ�Ľ���������Ҫ�����Ĺؼ��ʣ������ᵽ���û�����һ����һ������������ Web ҳ�棬Ȼ��Ӧ�ó��������Ĺؼ��ʽ�����������������������ʽ�����������ļ��Ͻ���������������������������淵������������û����ں�������У���������������˴��������ϻ�ȡ Web ҳ�棬Ȼ��������ϵͳ������Щ Web ҳ�沢���������ļ��С�
8 �ܽ���չ��
8.1 ����ܽ�
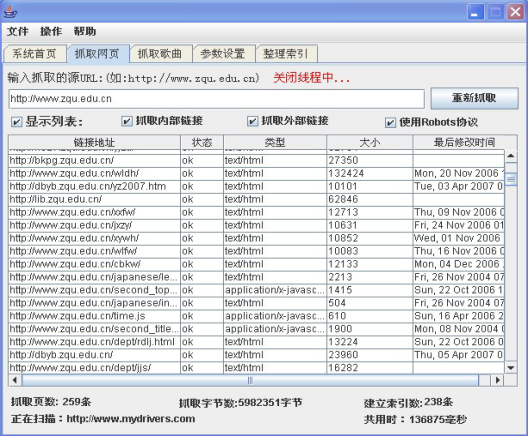
����ʵ�ֵ�WebCdf��������������Σ����������������������˲��ԣ�������WebSpiderץȡ��ҳ��������Ч�ʵIJ��ԣ���7-1��������1�����ڣ����������1Mbps��Ĭ��10��֩���̻߳�õġ�
��8.1 WebSpider-GetHTMLPageץȡ����վ������
��8.2 ϵͳ�ڸ���У��ҳ�в�ѯ���ԣ���GOOGLEΪ�ο���
�ӱ��е����ݿ�������������ų���վ��������������·��Ӱ�죬��Բ�ͬ��վҳ���С���ص㣬���ò�ͬ���߳������Ի�ø������Ч��������ҳƽ����С��Сʱ���ʵ�����߳��������Ը���ֵ������������������ҳƽ����С�Ƚϴ�ʱ�����߳������˹��࣬ռ�ù����ϵͳ��Դ����Ӱ���ٶȡ�
�����WebSpider����������������������Luke�������ļ������Կ���������¼����û���ظ���URL�������ĵ�ץȡ����Ҳ����������Ҳʵ���˷ִʣ������������Բ�ѯ�Ǻܹؼ��ġ�
�����Search��ѯ�������ı��֡�ǰ���ᵽWeb���������м�����Ҫ�ļ���ָ�꣬���ڱ��˵�ĿǰΪֹֻ������1������ҳ�����縲���ʺܵͣ�����֤ÿ�β�ѯ���ٻ��ʡ������ͱ���ץȡ�����ݽ������������صļ�¼���Լ�ǰ��ҳ�����ʶ��Ƚϸߣ���������С��Ӧ�õ���Ҫ����ѯʱ�����ܼ�¼���Ƚ��٣���Ӧʱ�伸���о���������������Կ������������ṹ�����ơ�
��Ȼ����ʵ�ֵ�WebCdf�������滹��һЩ����֮������Ŀǰֻ��ץȡ��̬��ҳ����ץȡ��̬��ҳ����������ͬIP��ͬ��ַ�������ֻ�ܸ�����ַ���֣����Ľ���ʱ��һЩ��ǩ��������ȫ���ˣ���Ӱ������������������Ը��ӵ����绷���������쳣�������������ȵȡ�ͬʱ��MP3��������Ķ����Խϲ��Դ��Ч�����Ա�֤����Щ������Ҫ�������ƺĽ��ĵط���
ͨ����Web��������ķ�������ƣ������˽���Web���������ԭ���ͽṹ��������Web��������Ļ������������Ҳʵ�����Լ����������棬����һ������������顣�����Լ�ʵ�ֵ��������棬���˻��һ��ѧϰ�о������ϵ���������ϣ�����ҵ���Ӧ�õ�һƬ�ռ䡣
8.2 δ��չ��
�������������������Ϣ��ը�����������Ż������IJ��Ϸ�չ��������������ļ���Ҫ��Խ��Խ�ߣ��������û�����Ҫ��
Ϊ���ô�����û������ʹ��������Ҫ������������д�����Ȼ��������Ĺ��ܣ�������Ϊ����ȫ�������������������Բ�ͬ���Ե��û�����δ������������Ӧ�þ�������Զ�����������Ĺ��ܡ�
��������ʶ�����Ͷ�ý�弼���ķ�չ��δ������������Ӧ�ÿ�������������Ϊ���룬��������������Ҳ���پ�����������Ϣ����������չ����ý����Ϣ��
һ��������������滹Ӧ�öԲ�ͬ���û�����ͬ�ļ����������в�ͬ�ļ�������������û���������Ӧ������
�������ĵķ�����δ���������潫��������Ҫ��չ���ƣ�
1�� ��Ȼ���ԣ����ȸ��ߣ�
2�� ��������������
3�� �ƽ����⣬ѧϰ����ϲ�ã�
4�� ��ͨ������Ͷ�ý�����[18]��
5�� ���Ի��ͱ��ػ���
��֮��δ������������Ӧ����Ϣ�����������ٶȸ��졢�������ȸ��ߺ��ܹ������û����Ի���Ҫ��չ���ƽ������ܻ��ġ����Ի��ġ�
�����
[1] �й�����������Ϣ���ģ�CNNIC��.��2003 ���й�����������Ϣ��Դ�������鱨�桷,2004
http://www.cnnic.com.cn/index/0E/00/12/index.htm
[2] �챦�ģ�������. ������������Ϣ��ȡ����[M]. �������廪��ѧ�����磬2003.
[3] Scott C. Deerwester, Susan T. Dumais, Thomas K. Landauer, George W. Furnas,and Richard A. Harshman. Indexing by Latent Semantic Analysis. Journal ofthe American Society of Information Science, 41(6):391--407, 1990
[4] Landauer, T. K., Foltz, P. W., and Laham, D. Introduction to Latent SemanticAnalysis. Discourse Processes, 25, 259-284, 1998
[5] J. Zobel, A. Moffat, and K. Ramamohanarao. Inverted files versus signature files for text indexing. ACM Transactions on Database Systems, 23(4):453--490,Dec. 1998
[6] �����“�ִ������ı��Ĵ����зּ���”���������棬������ѧ��������ѧ�о���
[7] ��С�����ƺ�ɣ�������. ��������——ԭ����������ϵͳ[M]. ��������ѧ�����磬2005.
[8] ������½����. JBuilder����[M]. ���������ӹ�ҵ�����磬2004.
[9] ����. ��Ӧ���м���ȫ�ļ�������——����Java��ȫ����������Lucene���[DB/OL]. http://www.chedong.com/tech/lucene.html,2002-08.
[10] лϣ��. ���������. ������ ���ӹ�ҵ�����磬2005
[11] ����. ����Դ�����ȫ�ļ�������Lucene�D�D���ܡ�ϵͳ�ṹ��Դ��ʵ�ַ���[DB/OL].
[12] ������Bruce Eckel��������� ����骵��� java���˼�루Thinking in java Third Edition��[M].��е��ҵ�����磬2006
[13] ���. ��ΰ. ���ܱ����� Ajax+lucene������������[M].��������磬2006
[14] M.Hall��L.Brown������ѧ����. Servlet��JSP���ı�̣���2�棩[M]. �������廪�����磬2004.
[15]��������˹���ǣ�Gospodnetic,O,��,(��)���غ�(Hatcher,E,)����̷�����; lucene in action ���İ�[M].���ӹ�ҵ�����磬2007
[16] ������.��������java�������ʵ�ý̳�[M].�廪��ѧ�����磬2005
[17] �Խ������ƺ�ɣ������£���������“�����еIJ�����ֲ�����”��
PKU_CS_NET_TR2002001��2002 ��1��
[18] �ڶص�. ��Larbin���������������[DB/OL].
http://www.example.net.cn/archives/2005/12/aioeaee.html,2005-12-16.
http://liyu2000.nease.net/article/Lucene/bachelor-paper.htm,2003-02.
ժ Ҫ
���Ż������IJ��Ϸ�չ�������ռ������ϵ���Ϣ���ڱ�ըʽ��������������ʱ�����ҵ���������Ҫ�����Ͼͳ���һ���dz��ؼ������⡣Ϊ�˽��������⣬Web�����������֮�����ˣ����õ��˷��ٷ�չ�������Ѿ���Ϊ�������Ͻ����ڵ����ʼ��ĵڶ����������
���ȣ����Ľ�����Web�����������ʷ����״��
��Σ����Ľ�����Web��������Ļ���ԭ���ͼ�����
�ٴΣ����ķ�����Web���������ϵͳ�ṹ�������ش�����֩�룬���������Web��ѯ�����������ֽ�������ϸ�����������ͬʱ��������������Java���������£�������ʵ��һ�����ÿ�Դ���߰���Web��������——WebCdf������Web��Ϣ�Ѽ�������WebSpider��Web��ѯ������Search������ϵͳ��
WebCdf���������ָ����Webҳ�濪ʼ�������ѻ�õ����ӷ��빤�����У�����ά���Ͻ��й����������������ÿ��ҳ���URL��ַ���ı����������������ݿ⣬Ȼ��Web���������տͻ����������ݿ��з���ҳ����Ϣ��
���Ľ��ܺ��о���һϵ����Web����������صļ�����������ҳץȡ�����������VSM������Ϣ��ȡ����Ϣ�����ȣ���Щ��������Ӧ�õ����������ϵͳ��Ʒ����С�
����ļؽ��������������δ����չ���ơ�
�ؼ���: ���������������棬��Ϣ��ȡ��Java
Web���������ԭ������
3.1 ����ԭ��
��������Ļ���ԭ����ͨ������֩�붨����web��ҳ�����У�Ȼ�����µ���ҳ��������ȡ�����ŵ����ص����ݿ��У��û��IJ�ѯ�������ͨ����ѯ���ص����ݿ����õ���
��������������֩���Զ�����ҳ�ϰ�ij�ֲ��Խ���Զ�����ݵ��������ȡ�������ɱ������������ڲ���Ҫ���ǵĽ��룬�ٶȵ��Լ������ߡ��串����ͼ�ʱ��Ҳ���Դ�����ߡ�Spider����WWW�ļ����������������Σ���¼ URL���ļ��ļ���ժҪ���ؼ��ֻ��������γ�һ���ܴ�����ݿ⣬�������ݿ�������⡢ժҪ���ؼ��ʺ�URL���ļ��Ĵ�С�������Լ��ʳ��ֵ�Ƶ�ʡ��������з�ʽΪ����һ����һ��URL��ʼ�����ʸ�URL��ָHTML�ļ������е�URLê����Ȼ��������Щ�µ�URLΪ��ʼ�㣬�������б���������ֱ����Ҳû�������������µ�URL Ϊֹ���ڼ�¼�µ�URLʱ�����Խ��з������жϣ�����ȥ������Ҫ����Ҫ��URL���ⲻ������˱����������ٶȣ�Ҳ�����������ļ��ڱ�����ռ�õĴ��̿ռ䡣
�������潫HTML ��ʽ�ļ�ȡ�����غ���һ��С�������еĸ�������ȥ���������HTML��ǩ���ű�������һ�����Խ����п����ڲ�ѯ�IJ��� (��ؼ��ֺ�һЩָ���ʵ� )�洢�����ݿ��У��γɱ��ز�ѯ���ݿ⣬�Ժ��ٲ�ʱ�Ͳ��ص�Զ��ȥ���»�ȡHTML ��ʽ�ļ��� ��
���û�����ؼ��ʣ�Keyword����ѯʱ�����������������û������ùؼ�����Ϣ��������ַ�����ṩͨ�����������ӡ�������������ݼ�����ʽ��Ҫ�ǹؼ��ֵ�ƥ�䷽ʽ���緺ƥ�䡢ģ��ƥ�䡢����ƥ���Լ���ؼ��ֵĴ�����ʽ�� ����Ϊ�û��ṩȫ��������Լ���Լ��������ڲ�����ϵ�IJ�ѯ��ʽ�����Բ�ѯ�������ij���㷨�������ֺ�����
ͨ��һ�� Web��������ļܹ�[7]��Ϊǰ�˺ͺ�������֣�����ͼ2-2����ʾ����ǰ�������У��û������������ṩ�Ľ���������Ҫ�����Ĺؼ��ʣ������ᵽ���û�����һ����һ������������ Web ҳ�棬Ȼ��Ӧ�ó��������Ĺؼ��ʽ�����������������������ʽ�����������ļ��Ͻ���������������������������淵������������û����ں�������У���������������˴��������ϻ�ȡ Web ҳ�棬Ȼ��������ϵͳ������Щ Web ҳ�沢���������ļ��С�
8 �ܽ���չ��
8.1 ����ܽ�
����ʵ�ֵ�WebCdf��������������Σ����������������������˲��ԣ�������WebSpiderץȡ��ҳ��������Ч�ʵIJ��ԣ���7-1��������1�����ڣ����������1Mbps��Ĭ��10��֩���̻߳�õġ�
��8.1 WebSpider-GetHTMLPageץȡ����վ������
| ��վ���� | ץȡ��ҳ�� | ���������� | �������� |
| ����ǰ�� | 299 | 292 | 3865KB |
| ���������� | 295 | 251 | 3012KB |
| Matrix-��java���� | 221 | 161 | 3604KB |
| ������ | 150 | 148 | 4678KB |
| �й�ѧ���� | 158 | 143 | 4850KB |
| ѧ���� | 142 | 139 | 4947KB |
| ����Ͱ� | 39 | 31 | 5649KB |
| �ѷ��� | 29 | 28 | 5515KB |
��8.2 ϵͳ�ڸ���У��ҳ�в�ѯ���ԣ���GOOGLEΪ�ο���
| �ؼ��� | ���� | ��ȫ�� | ���� |
| �㶫��ҵ��ѧ | 0.95 | 0.95 | ���� |
| ����������ѧ | 0.93 | 0.96 | ���� |
| ��ɽ��ѧ | 0.96 | 0.87 | ���� |
| ���ϴ�ѧ | 0.89 | 0.91 | ���� |
| ���ݴ�ѧ | 0.90 | 0.94 | ���� |
| ���ڴ�ѧ | 0.99 | 0.93 | ���� |
| ����ʦ����ѧ | 0.97 | 0.94 | ���� |
| ��������ѧԺ | 0.94 | 0.94 | ���� |
�ӱ��е����ݿ�������������ų���վ��������������·��Ӱ�죬��Բ�ͬ��վҳ���С���ص㣬���ò�ͬ���߳������Ի�ø������Ч��������ҳƽ����С��Сʱ���ʵ�����߳��������Ը���ֵ������������������ҳƽ����С�Ƚϴ�ʱ�����߳������˹��࣬ռ�ù����ϵͳ��Դ����Ӱ���ٶȡ�
�����WebSpider����������������������Luke�������ļ������Կ���������¼����û���ظ���URL�������ĵ�ץȡ����Ҳ����������Ҳʵ���˷ִʣ������������Բ�ѯ�Ǻܹؼ��ġ�
�����Search��ѯ�������ı��֡�ǰ���ᵽWeb���������м�����Ҫ�ļ���ָ�꣬���ڱ��˵�ĿǰΪֹֻ������1������ҳ�����縲���ʺܵͣ�����֤ÿ�β�ѯ���ٻ��ʡ������ͱ���ץȡ�����ݽ������������صļ�¼���Լ�ǰ��ҳ�����ʶ��Ƚϸߣ���������С��Ӧ�õ���Ҫ����ѯʱ�����ܼ�¼���Ƚ��٣���Ӧʱ�伸���о���������������Կ������������ṹ�����ơ�
��Ȼ����ʵ�ֵ�WebCdf�������滹��һЩ����֮������Ŀǰֻ��ץȡ��̬��ҳ����ץȡ��̬��ҳ����������ͬIP��ͬ��ַ�������ֻ�ܸ�����ַ���֣����Ľ���ʱ��һЩ��ǩ��������ȫ���ˣ���Ӱ������������������Ը��ӵ����绷���������쳣�������������ȵȡ�ͬʱ��MP3��������Ķ����Խϲ��Դ��Ч�����Ա�֤����Щ������Ҫ�������ƺĽ��ĵط���
ͨ����Web��������ķ�������ƣ������˽���Web���������ԭ���ͽṹ��������Web��������Ļ������������Ҳʵ�����Լ����������棬����һ������������顣�����Լ�ʵ�ֵ��������棬���˻��һ��ѧϰ�о������ϵ���������ϣ�����ҵ���Ӧ�õ�һƬ�ռ䡣
8.2 δ��չ��
�������������������Ϣ��ը�����������Ż������IJ��Ϸ�չ��������������ļ���Ҫ��Խ��Խ�ߣ��������û�����Ҫ��
Ϊ���ô�����û������ʹ��������Ҫ������������д�����Ȼ��������Ĺ��ܣ�������Ϊ����ȫ�������������������Բ�ͬ���Ե��û�����δ������������Ӧ�þ�������Զ�����������Ĺ��ܡ�
��������ʶ�����Ͷ�ý�弼���ķ�չ��δ������������Ӧ�ÿ�������������Ϊ���룬��������������Ҳ���پ�����������Ϣ����������չ����ý����Ϣ��
һ��������������滹Ӧ�öԲ�ͬ���û�����ͬ�ļ����������в�ͬ�ļ�������������û���������Ӧ������
�������ĵķ�����δ���������潫��������Ҫ��չ���ƣ�
1�� ��Ȼ���ԣ����ȸ��ߣ�
2�� ��������������
3�� �ƽ����⣬ѧϰ����ϲ�ã�
4�� ��ͨ������Ͷ�ý�����[18]��
5�� ���Ի��ͱ��ػ���
��֮��δ������������Ӧ����Ϣ�����������ٶȸ��졢�������ȸ��ߺ��ܹ������û����Ի���Ҫ��չ���ƽ������ܻ��ġ����Ի��ġ�
�����
[1] �й�����������Ϣ���ģ�CNNIC��.��2003 ���й�����������Ϣ��Դ�������鱨�桷,2004
http://www.cnnic.com.cn/index/0E/00/12/index.htm
[2] �챦�ģ�������. ������������Ϣ��ȡ����[M]. �������廪��ѧ�����磬2003.
[3] Scott C. Deerwester, Susan T. Dumais, Thomas K. Landauer, George W. Furnas,and Richard A. Harshman. Indexing by Latent Semantic Analysis. Journal ofthe American Society of Information Science, 41(6):391--407, 1990
[4] Landauer, T. K., Foltz, P. W., and Laham, D. Introduction to Latent SemanticAnalysis. Discourse Processes, 25, 259-284, 1998
[5] J. Zobel, A. Moffat, and K. Ramamohanarao. Inverted files versus signature files for text indexing. ACM Transactions on Database Systems, 23(4):453--490,Dec. 1998
[6] �����“�ִ������ı��Ĵ����зּ���”���������棬������ѧ��������ѧ�о���
[7] ��С�����ƺ�ɣ�������. ��������——ԭ����������ϵͳ[M]. ��������ѧ�����磬2005.
[8] ������½����. JBuilder����[M]. ���������ӹ�ҵ�����磬2004.
[9] ����. ��Ӧ���м���ȫ�ļ�������——����Java��ȫ����������Lucene���[DB/OL]. http://www.chedong.com/tech/lucene.html,2002-08.
[10] лϣ��. ���������. ������ ���ӹ�ҵ�����磬2005
[11] ����. ����Դ�����ȫ�ļ�������Lucene�D�D���ܡ�ϵͳ�ṹ��Դ��ʵ�ַ���[DB/OL].
[12] ������Bruce Eckel��������� ����骵��� java���˼�루Thinking in java Third Edition��[M].��е��ҵ�����磬2006
[13] ���. ��ΰ. ���ܱ����� Ajax+lucene������������[M].��������磬2006
[14] M.Hall��L.Brown������ѧ����. Servlet��JSP���ı�̣���2�棩[M]. �������廪�����磬2004.
[15]��������˹���ǣ�Gospodnetic,O,��,(��)���غ�(Hatcher,E,)����̷�����; lucene in action ���İ�[M].���ӹ�ҵ�����磬2007
[16] ������.��������java�������ʵ�ý̳�[M].�廪��ѧ�����磬2005
[17] �Խ������ƺ�ɣ������£���������“�����еIJ�����ֲ�����”��
PKU_CS_NET_TR2002001��2002 ��1��
[18] �ڶص�. ��Larbin���������������[DB/OL].
http://www.example.net.cn/archives/2005/12/aioeaee.html,2005-12-16.
http://liyu2000.nease.net/article/Lucene/bachelor-paper.htm,2003-02.
Ŀ ¼
1 ���� 1
1.1���� 1
1.2 ��������ķ�չ��ʷ 2
1.3 �����������״���� 3
1.4 �� 4
2 ��ؼ��� 5
2.1 ���ץȡ���� 5
2.2 ��������� 6
2.3 ��Ϣ�������� 8
2.4 ����������� 8
2.5 ������ؼ��� 9
2.5.1���ݴ洢 9
2.5.2 ���ķִ� 10
2.6 �� 10
3 Web���������ԭ������ 11
3.1 ����ԭ�� 11
3.2 ��ҳ�Ѽ� 12
3.3 Ԥ���� 13
3.4 ��ѯ���� 14
3.5 ��������ļ���ָ�� 15
3.6 �� 15
4 Web���������ϵͳ�ṹ 16
4.1ϵͳ���� 16
4.2ϵͳ�������ֹ��� 17
4.2.1����֩�� 17
4.2.2 ��������� 18
4.2.3 Web��ѯ������ 18
4.3 ϵͳ����������Դ 18
4.4 �� 19
5 ����Spider��ʵ�� 20
5.1 Pages-Spider��ʵ�� 20
5.1.1 Pages-Spider���� 20
5.1.2 Pages-Spider�ṹ���� 20
5.1.3 Pages-Spider����ṹ 22
5.1.4 Pages-Spiderʵ�� 26
5.1.5�� 28
5.2 Mp3-Spider��ʵ�� 29
5.2.1 Pages-Spider����ṹ 29
5.2.2 Mp3s-Spider�ṹ���� 29
5.2.3 Mp3s-Spiderʵ�� 31
5.2.1 �� 33
6 ����Lucene��ȫ������ʵ�� 34
6.1 Luceneȫ�ļ������� 34
6.2 Lucene�����Է��� 34
6.2.1 Lucene�ĺ��IJ���——���������� 34
6.2.2 Lucene��ضȻ��ֹ�ʽ 35
6.2.3 Lucene���� 36
6.3 Lucene�Ĺ���ԭ�� 37
6.3.1 ȫ�ļ�����ʵ�ֻ��� 37
6.3.2 Lucene�������� 37
6.3.3 ���ķִ����� 38
6.4�������ܵ�ʵ�� 39
6.4.1 �ִ�ʵ�� 39
6.4.2 PAGES-��������ʵ�� 39
6.4.3 MP3S-��������ʵ�� 40
6.5�����ϲ���ʵ�� 41
7 ����Tomcat�ķ�����ʵ�� 43
7.1 Tomcat���� 43
7.2 �ͻ������ 43
7.3 �������� 46
7.4 ����Tomcat��Ŀ 48
7.5 �� 49
8 �ܽ���չ�� 50
8.1 ����ܽ� 50
8.2 δ��չ�� 51
����� 53
�� л 55