

苏ICP备112451047180号-6
基于SPSS Clementine的数据挖掘软件的分析研究及应用
|
一、选题简介、意义 选题简介 因为现在互联网上的信息具有数量巨大、没有规则以及很容易重复的特征,导致人们现在不能快速地从网络信息中获取所需要的信息,这让我们的生活十分的不方便,所以如何在互联网上使用Web数据挖掘技术就很重要。 我们了解Web挖掘在大数据中大概被划分为三类,分别是Web内容挖掘、Web结构挖掘以及Web使用模式挖掘。在这里我们主要介绍其中之一:Web使用模式挖掘,它是对用户浏览及访问的网站数据进行观察、建模以及分析,从而观察用户的浏览行为,理解用户在浏览中的趣向,以便对浏览者供应更加具有特色的服务,又或者是对网站结构进一步改善。 Web技术挖掘就是在实际应用中,提前在巨大得、残缺得、有杂音得、不清楚得、随机的数据中,将隐藏在里面的、人们事前不清楚的、但是又隐含在里面的,有用的情报消息提炼出来的经过。 Web技术挖掘是近年来才发展起来的新兴信息技术。它将数据库技术,人工智能技术,统计技术和数学与其他学科知识的整合,在数据中将人们不清楚或者有用的知识提取出来。Web挖掘主要是挖掘寻找现象之间事先未知的关系。 选题意义: Web数据挖掘是一个高度集成的技术,它可以在我们从网站中获取到的所需的信息中,使我们观察网站用户的访问数据,从而了解用户访问网站的特点,以便为用户提供适合他们趣向的服务,或者是为网站结构提供更好的改善方案。 Web数据挖掘有以下几个特点: 1. 异构数据库环境。在网络上,每个站点可以看作是一个数据源,其中的信息内容和组织结构都是不同的,有这些数据源之间的差异可能会构成一个巨大的异构数据库。 2.在世界各地的Web 服务器上都有Web,构成了分布式的数据源。 3.动态性强。网络上的信息源具有高度动态的特性。因为人们会经常对Web查询,网页提供者也会不定期地更新,所以导致了各个站点的访问信息和浏览记录的更新非常频繁,来自网页的信息更新速度也很快。 4.半结构化。Web上的数据是一种非完全结构化的数据,没有特定的模型描述。 5.多样复杂性。复杂的网络信息资源中,它将文本数据,超链接,图片,影像视频数据和其他数据资源都包含在其中。 |
|
|
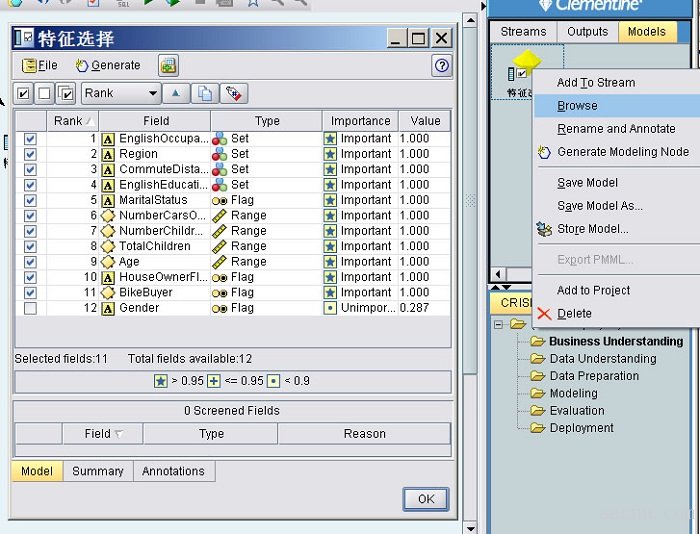
二、课题综述(课题研究,主要研究的内容,要解决的问题,预期目标,研究步骤、方法及措施等) 课题研究: SPSS Clementine这款软件在Web挖掘领域使用频率很高,它拥有的先进技术超越许多软件。挖掘任务可以在多个领域扩展,范围很广,包括各种数据的技术,数据挖掘的过程可以更容易表现,便于我们理解。SPSS Clementine软件挖掘数据过程简单,容易上手操作,也可以使用算法语言编写模型对数据进行操作,让数据更加具有层次感,保证数据更加直观、有效。 主要研究的内容: 基于web的数据挖掘软件的分析研究,了解数据挖掘系统的目标与特点,了解系统的功能设计与模块划分,从而对网络方面有更深入的了解。 解决的问题: 基于Web的数据挖掘技术,不仅能做出明智的选择可靠的数据源,数据源选择和内容无关的固定格式,还可以让自己拥有一个维护成本低廉,可靠的数据抽取系统。 预期目标: 主要利用Web数据挖掘来解决四类问题。 1. 分类问题。分类问题属于预测问题,但与常见问题不同的是,他侧重于预测的结果是范畴。 2. 聚类问题。聚类问题是不可预测的,它主要是针对一组对象被分为几组问题。 3. 相关联问题。世界上的一切都有千丝万缕的联系,我们要善于发现。 4. 预测问题。此处说的问题是狭义的的预测。 研究步骤: 1. 标识数据源并把它映射成 XHTML。 2. 查找数据内的引用点。 3. 将数据映射成 XML。 4. 合并结果并处理数据。 研究方法、措施: 1.懂得SPSS Clementine这款软件的一般操作过程。 2.针对自己所需获取数据源。 3.使用合适的模型分析获取到的数据。 4.得出实验的结论。 |
|
|
三、设计(论文)体系、结构(大纲) 1.设计体系 (1)对Web数据挖掘技术的了解。(2)深入了解在动态工作环境中要选择合适的信息源,才能简单工作。(3)对挖掘技术进行分组,比较其功能,可以利用挖掘工具来实现。(4)选择合适的挖掘技术,并加深对挖掘技术的了解。 2.大纲 数据挖掘过程的主要是数据的准备、数据的理解、数据模型的建立、对模型的评估以及模型的应用。 |
|