
苏ICP备112451047180号-6
摘要
随着测量对象的数据增加,重要变量选择增多,多变量增加缓解和改善性变得越来越重要.在很多在文献中的数据分析和统计的变量选择中,它是一个挑战.因此,我们提出了审查现有的模型,用偏最小二乘回归对一个高通量数据的建模方法进行变量选择方法,本文的目的主要是在这样一种收集方式下得到一个短期的方法,读者很容易理解的其特点的方法,并获得了在一个基础下,选择一个合适的方法,为自己使用.对于每一个方法,我们也为读者做进一步的阅读,并在文献中提供参考,并提供软件的可用性.
1.介绍
如许多现实世界中的应用程序所经历的一样,现在呼吁大量数据下用多变量方法进行数据分析.随着技术的进步,每增加一个变量的数量,样品逐渐减少.
测量基因是表达在生物信息学中是一个很好的例子,该技术已经开发出或多或少的单变量的方法,如聚合酶链反应(聚合酶链反应),用于测量东部时间序列标签的高度多元微阵列对mRNA的相对含量测定,最后对新开发的生物技术促进DNA / RNA的高速测序.为了深入了解像代谢和基因调控这样的复杂系统,多因素的考虑是必要的,在这方面技术的进步已成为最大的进口.然而,技术扩张的缺点是在统计模型中存在着包括不相关变量的风险.为了最大限度地减少这些变量的影响,一些数据减少通常是必要的,无论是通过投影方法,变量选择或两者的组合这里描述的问题是典型的许多领域的科学.许多作者,例如[1-5],已经解决.
这个问题,有许多建议的方法处理所谓的大的对小的氮问题[ 1 ],即,许多变量和一些样本.一些方法在时间的磨损中生存被数据分析所收养,另一些人则是一个在竞争中无法达到的奇迹.这就是科学进步了.然而,每一个现在,然后,它是必要的使用和审查在一个特定领域的研究现状,本文将为变量选择方法只在偏最小二乘回归(PLSR)[6-7].
这种方法已被证明是一个非常灵活的方法,多变量数据分析和应用数量是研究生物信息学等领域稳步增加,机器学习和CHEMOM 英国皇家特许测量师学会(见图1,资料来源:http://wokinfo.com/搜索关键词"偏最小二乘法"或"投影潜结构").它是一种有监督的专门解决问题的方法,他们在多变量问题作出良好的预测,看到[ 1 ].在其原来的形式没有实现变量选择的方法下,由于方法的重点是找到相关的线性解释变量的空间,大量的方法的变量选择方法已经被提出.本文的目的是给读者一个对PLSR变量选择可用的方法概述和解决每个方法或相似的其他方法的潜在性.
在我们关注它可能是一个值得给予方法进行变量选择的方法.偏最小二乘法是一种基于投影的方法,原则上应可以忽略的变量空间,跨越的方向,嘈杂的变量.因此,预测变量的选择似乎是不必要的,因为上下变量加权的PLS估计固有的特性.然而,非常大的磷和小氮肥仍然可以破坏的偏最小二乘回归结果.例如,在这种情况下,由于单因素反应[2]的PLS估计的渐近一致性问题从一个预测的角度来看,大量的不相关的变量可能会产生很大的变化,测试预测集[ 8 ].这两点缺陷可能与事实的PLS算法越来越近,发现问题的p维变量空间相关的子空间的正确尺寸变量增加时数简化.关于这一问题的讨论,见例5.这些例子激励变量选择的改进估计/预测的性能,并讨论了[ 3-4 ].变量的选择可以提高我的模型的性能,但同时也可能消除一些有用的冗余模型,并使用一个小数量的变量的预测意味着我们把每个变量的影响较大的在最后的模型[ 9 ].在这方面,选定的变量的一致性也对系统模型的解释和理解的研究.因此,动机的分析,而可能是确定一组重要的变量进行进一步的研究,可能其他技术或方法.这两种动机可能有些矛盾,为实现更好的解释,它可能需要妥协的P的预测性能Lsr模型[11].
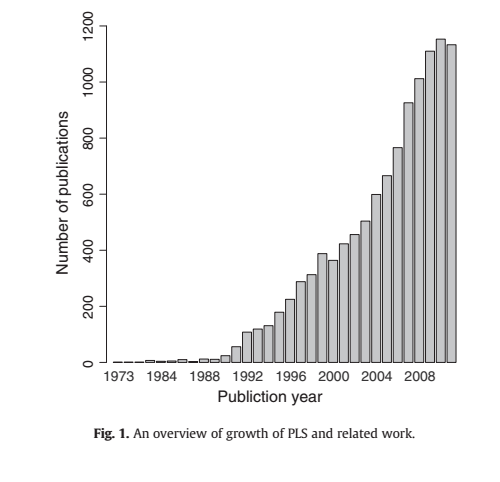
图1.请与相关工作概述
本文组织如下.首先,我们在2节目前最常见的偏最小二乘回归算法,正交分PLSR,因为我们将反复讨论时的各种算法美国变量选择方法.然后,在第3节中,我们提出了三个主要类别,过滤器的方法,包装方法和嵌入式方法的变量选择方法.在讨论结束时,我们提出的变量选择方法之间的联系.
3.在偏最小二乘变量选择方法
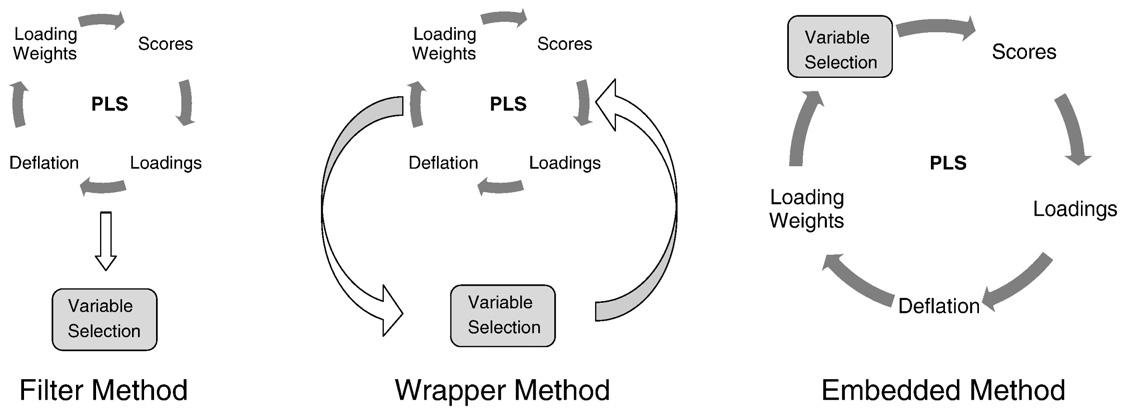
基于多变量的选择定义方法我们可以归纳变量选择方法分为三大类:过滤,包装,和嵌入方法.这种分类也同样是你SED的[ 13 ].在我们详细介绍一下具体的选择方法之前,我们给出了一个简短的解释这三类
(1)过滤方法:
这些方法使用(随意修改)提出了从单纯的识别方法算法重要变量的子集.目的是变量识别.
(2)包装方法:
通过滤波方法确定的变量可以被输送回重新拟合的PLSR模型产量减少模型在这种情况下,我们的包装方法.方法是麦只有区分相关滤波方法的选择以及如何"包装"的实施.这些方法主要是基程序迭代之间的拟合模型和变量选择.
(3)嵌入方法:
变量的选择是一个综合的算法部分改性方法.因此,这些方法在组件中的变量选择.
这些方法之间的差异也如图2所示.在图3中,本文中讨论的变量选择方法的概述.
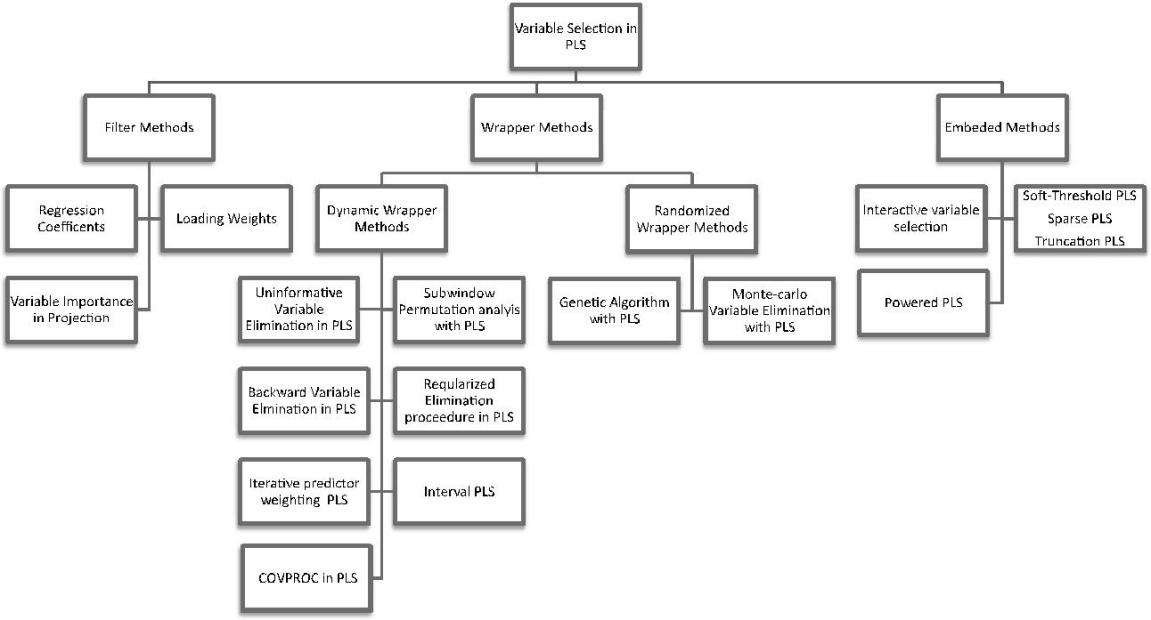
3.1过滤方法
两步滤波方法的选择变量,首先偏最小二乘回归模型拟合的数据,然后选择变量是通过引入一个阈值的测量进行了一些相关从拟合的模型得到的CY.通常这些方法是快速和易于计算,但与所选择的变量的预测相关性,这些方法没有指示.方法需要某种滤波措施代表各自变量的响应关系.一个阈值的过滤器的措施是必需的分类变量作为选择或不,因此选择的选择是严重影响所选择的阈值和选择一个好的阈值水平可能是有问题的.在偏最小二乘法中的滤波措施的例子包括:装载量向量,最小二乘法投影系数,重投影.
3.1.1.装载重量
从拟合的模型,这是对一些部件进行了优化,可能通过交叉验证,加载重量可以作为一个衡量的变量选择,[ 14,3].对于每一个组件,在绝对值的某个阈值以上的负载量的变量可以选择.这也被称为硬阈值,并建议由[ 15 ].例如,负载重量从优化模型中提取用于波长测定有效的歧视.一个方便的输出和滤波措施从PLSR模型大多数软件,使用r实施,例如
(http://cran.r-project.org/web/packages/pls/).
3.1.2 回归系数
一个可能性是使用回归系数的向量(β),这是一个单一的衡量每个变量之间的关联和响应.再次,变量有小的绝对值这个过滤器的措施可以消除[ 4 ].在这种情况下阈值可以基于意义考虑折裂或引导[ 21 ]中已广泛采用研究(例如[22,23]).以这种方式,而不是依赖于单一的观察的过滤器的措施,分布或变化也被认为是.在这方面,可以给更多的引导有效的回归系数估计比刀切,但在额外的计算时间[ 21 ]成本.对回归系数的使用作为过滤措施包括波长选择的例子[ 24,23 ]功能和基因选择在左机械心室辅助装置之间的关系建模(LVAD)支持的时间和在人心中的[ 25 ]基因表达的变化.回归n系数也从PLSR软件标准输出,包括R.
讨论
在本文中,一系列的PLSR的变量选择方法已被提出并分为三大类;滤波方法,包装方法和嵌入方法.分类是基于变量选择方法.滤波方法简单并提供快速排名,并给出在这方面的一些重要的变量测量.过滤器的限制方法是一个事实,即一些"阈值"必须指定,以选择一个子集的变量,因此选择是阈值的依赖性和没有适当的交叉验证,这是一个不可靠的结果.使用交叉验证的阈值选择快速通过过滤器的方法,在包装的方法,其中变量选择是包装的模型.包装方法在ITER运行性的方式,在每个运行模型性能进行了实测,变量是基于滤波器的措施和选择排序进行.连同这些改进模型的可解释性电子方法也提供性能指标.包装方法通常是耗时的,需要大量的复杂度参数进行调整.嵌入方法包括变量选择,选择一个非常好的结构形式,通过变量的选择作为一个完整的建模步骤.然而,大多数的嵌入式方法,也可以运行跨验证的偏最小二乘算法本身的选择分量的阈值参数,这将不可避免地放缓的算法的速度.但这里有一个例外是人口,而不是运行交叉验证选择最优的功率参数依据关于规范相关性最大化的教育.
最后值得一提的是适当的核算的重要性时,大量的变量有变量选择,这些变量将永远是不相关的变量,反过来也是一样的,因为机会,即使经过验证.因此,在变量选择的过程中,过度拟合的风险是非常大的.不同变量之间的差异是怎样的,关于过度拟合的风险的选举方法,过度拟合问题的讨论,比如Jouan-Rimbaud等人[ 76 ]和[ 77 ]讨论这个问题时,运用佐治亚的一些方法时会倾向于利用数据超过其他重要变量的搜索,在y-information选择的变量子集的淘汰落后的背景下,一个典型的更灵活的方法运行过度拟合会有更大的风险.为了安全起见,无论哪种方法选择,测试的样品应使用独立作为选定变量的最终评估.